
Si quieres que un agente (interno o de cara al cliente) funcione de verdad, necesita una base sólida: documentación actualizada, fuentes claras y capacidad de buscar el fragmento correcto. Ahí entra el RAG (Retrieval-Augmented Generation): en lugar de pedirle al modelo que “adivine”, le hacemos consultar tus documentos (catálogo, políticas, SOPs, tickets, fichas técnicas, bases de datos) y responder usando ese contexto.
En la práctica, RAG es el “sistema nervioso” que permite que la IA sea fiable, actualizable y gobernable: cambias un documento y la respuesta cambia, sin reentrenar nada.
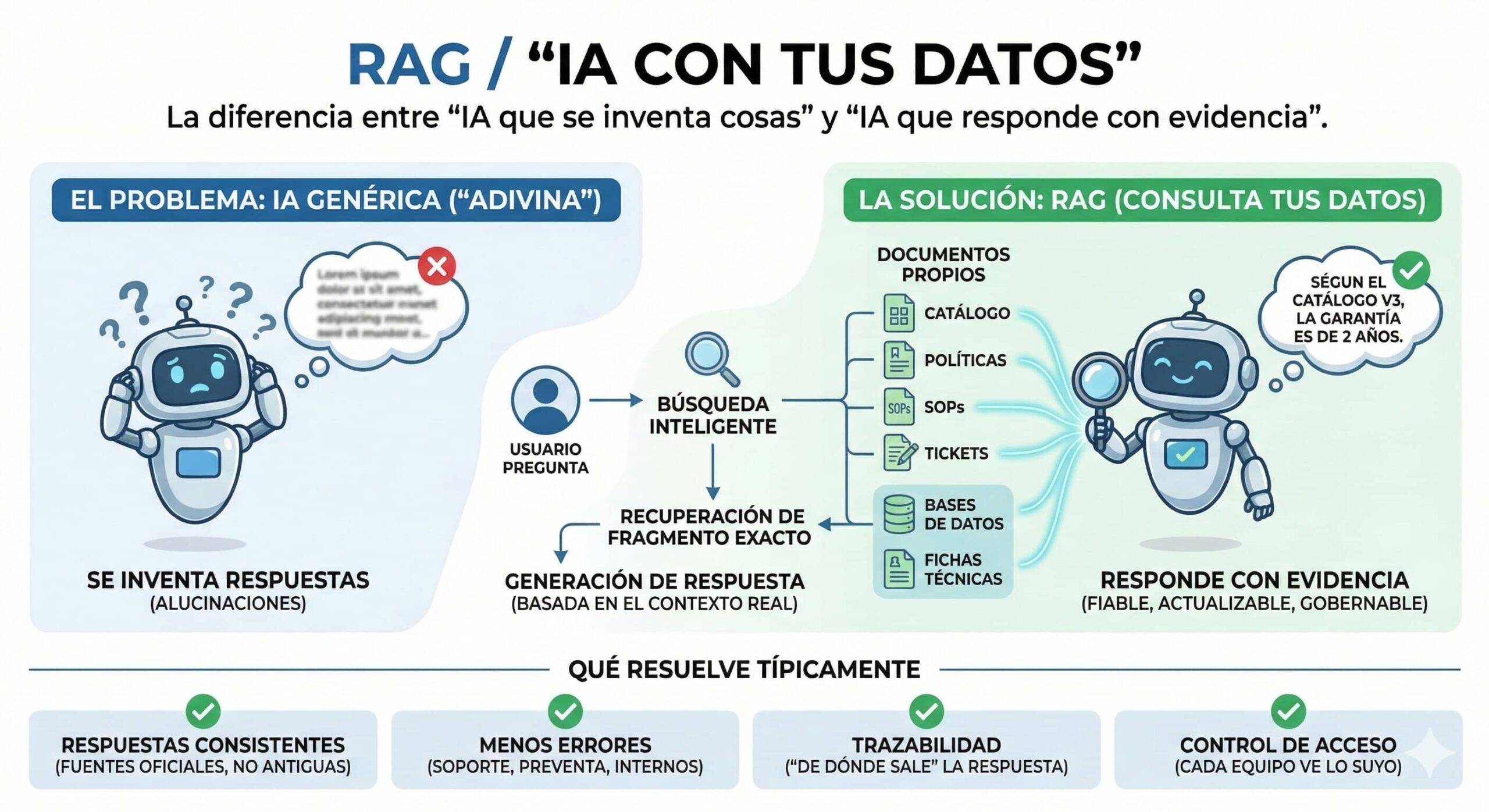
IA + “buscador” de tu conocimiento: el sistema recupera el contenido relevante y el modelo responde usando ese contexto.
IA + “buscador” de tu conocimiento: el sistema recupera el contenido relevante y el modelo responde usando ese contexto.
PDFs, Word, FAQs, Notion/Confluence, Google Drive, fichas de producto, políticas, tickets, CRM/ERP (según permisos), CSV/Excel estructurados.
No, pero las reduce muchísimo si se hace bien. Además, se diseñan límites: cuando no hay evidencia suficiente, el sistema debe pedir aclaración o escalar.
Con un proceso simple: documentos “fuente” + rutina de actualización (automática o semiautomática). Lo importante es definir quién mantiene qué y con qué periodicidad.
Entrenar es caro, lento y difícil de actualizar. RAG es más rápido: cambias el documento y cambia la respuesta. Para la mayoría de empresas, RAG es el 80/20.
Se controla con permisos, minimización, segmentación de fuentes, y límites sobre qué se puede consultar o registrar. Si hay alta sensibilidad, se recomienda arquitectura y herramientas más “enterprise”.
Reducción de errores, consistencia de respuesta, menor tiempo de búsqueda de info, reducción de tickets escalados, y adopción interna.
Reducción de errores, consistencia de respuesta, menor tiempo de búsqueda de info, reducción de tickets escalados, y adopción interna.